Related Projects
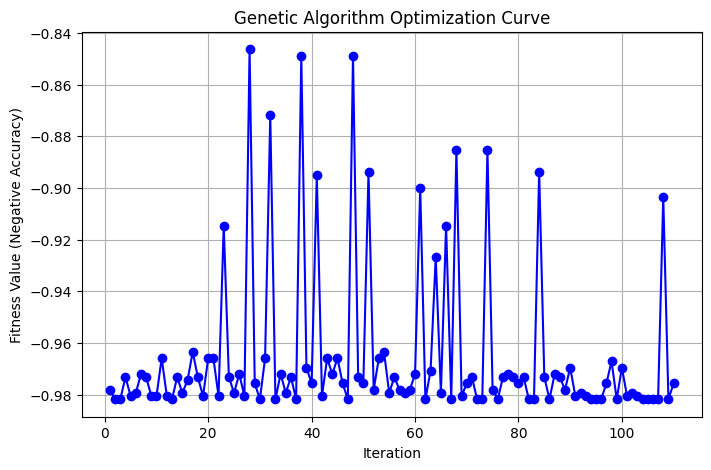
Optimizing Heart Disease Prediction Models Using Genetic Algorithm and Neural Architecture Search
Machine Learning
View Details

A text-classification pipeline that uses TF-IDF features and a Multinomial Naïve Bayes classifier to predict the language of input sentences.
The notebook loads the “Language Detection.csv” dataset into pandas (10 337 entries with “Text” and “Language” columns), then splits into training and test sets. It vectorizes text using TfidfVectorizer, fits a MultinomialNB model, and evaluates performance via accuracy score, confusion matrix, and classification report .
Machine Learning
View Details