Related Projects
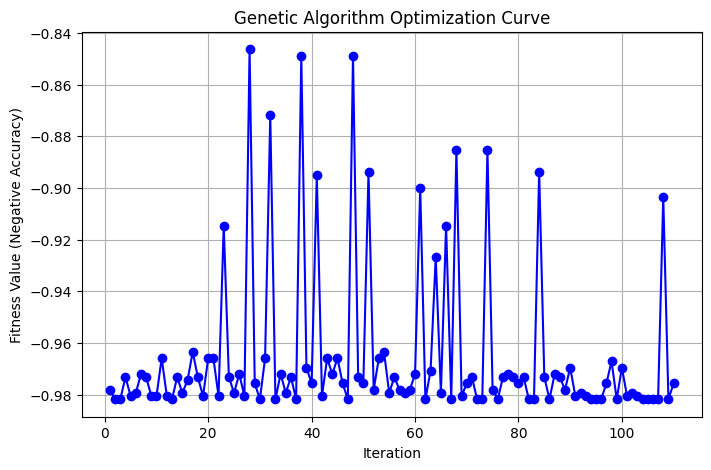
Optimizing Heart Disease Prediction Models Using Genetic Algorithm and Neural Architecture Search
Machine Learning
View Details

A pipeline to classify breast tumors (malignant vs. benign) using a Decision Tree model on clinical feature data.
The notebook begins by loading the Breast cancer.csv dataset with pandas and displaying the first rows . It drops non-predictive columns (Unnamed: 32), encodes the target diagnosis (M → 1, B → 0) , and scales features with a MinMaxScaler. After splitting into train/test sets, it trains a DecisionTreeClassifier(random_state=42), then evaluates performance via accuracy, precision, recall, F1-score, and confusion matrix.
Machine Learning
View Details