Back to Projects
Project Overview
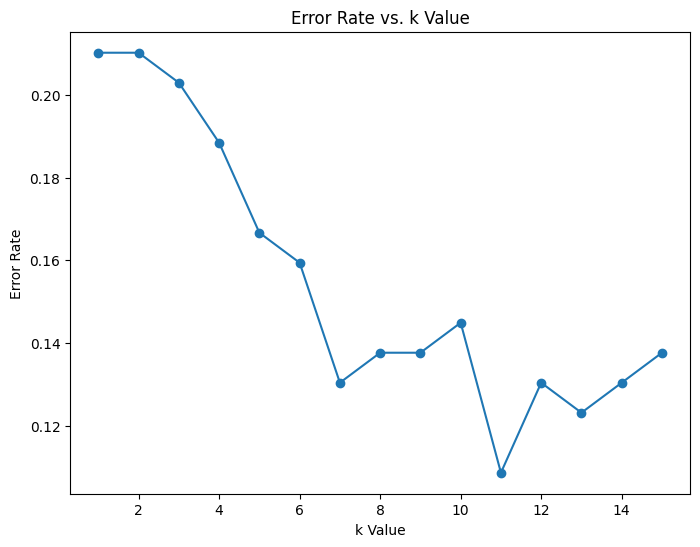
The project reads the “Credit_Card_Fraud_Detection.csv” dataset with pandas, examines its structure, and applies StandardScaler to normalize features. It splits data into training and test sets, then uses GridSearchCV to find the best KNeighborsClassifier hyperparameters. An error-rate vs. k plot illustrates tuning choices,and final evaluation metrics include accuracy_score, classification_report, and confusion_matrix.
Project Files
HTML File
Downloading is not permitted without the owner's permission.
Project Details
- Completion Date December 2024
- Category Machine Learning
- Project Type HTML File
Project Preview