Back to Projects
Project Overview
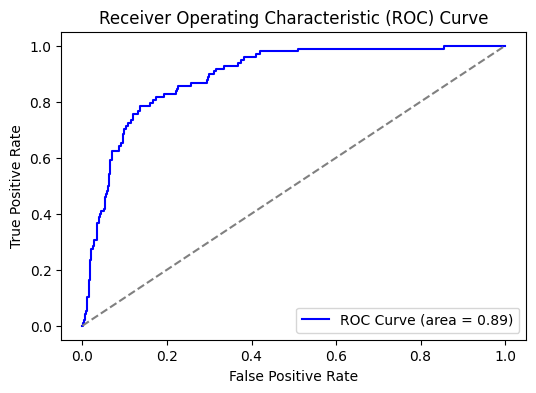
The notebook begins by loading the “bank.csv” dataset (semicolon-delimited) into pandas and displaying its first few rows . It proceeds with exploratory data analysis—visualizations and mermaid diagrams for workflow documentation—then preprocesses features (e.g. encoding categorical variables), splits into train/test sets, and applies classification algorithms (e.g., Logistic Regression, Random Forest), evaluating via accuracy, confusion matrices, and classification reports.
Project Files
HTML File
Downloading is not permitted without the owner's permission.
Project Details
- Completion Date May 2025
- Category Data Analysis
- Project Type HTML File
Project Preview